Littlewood’s three principles provide useful intuition for those first learning measure theory:
“The extent of knowledge [of real analysis] required is nothing like as great as is sometimes supposed. There are three principles, roughly expressible in the following terms:
- Every set is nearly a finite sum of intervals.
- Every function is nearly continuous.
- Every convergent sequence is nearly uniformly convergent.”
– John Littlewood
In my last post, I furnished a proof of the first statement. I should mention that in passing that the principle is true in  as well: every open ball in is nearly a finite union of cubes (the only change is that you cannot assume that any open set is the disjoint union of open cubes). Today I’ll go out of order and prove the third principle. The reason for this order will be made clear Friday, when I’ll employ the third principle to prove the second one.
as well: every open ball in is nearly a finite union of cubes (the only change is that you cannot assume that any open set is the disjoint union of open cubes). Today I’ll go out of order and prove the third principle. The reason for this order will be made clear Friday, when I’ll employ the third principle to prove the second one.
The third principle states that “every convergent sequence is nearly uniformly convergent.” Let’s recall the difference between these two modes of convergence. To do so, I’ll employ an analogy.
Let’s fix a sequence  of complex-valued functions with
of complex-valued functions with  and let’s play the following game. I have two bags, labeled and
and let’s play the following game. I have two bags, labeled and  , with the first bag containing every element of and the second bag containing every positive real number. You have one bag, labeled
, with the first bag containing every element of and the second bag containing every positive real number. You have one bag, labeled 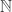 , which contains every natural number. At the beginning of the game, you name a complex-valued function
, which contains every natural number. At the beginning of the game, you name a complex-valued function  . Also, since I’m no Hercules, we’ll make finitely measured, i.e.
. Also, since I’m no Hercules, we’ll make finitely measured, i.e.  .
.
In the first turn, I pull an  out of the bag labeled . If you can find me an
out of the bag labeled . If you can find me an  large enough in
large enough in  so that
so that 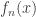 is within
is within  for all
for all  , then you win the first round.
, then you win the first round.
Then, in the second turn, I pull an out of the bag labeled , but this time I also pull an  out of the bag labeled . If you can find me an large enough in so that is within for this specific , then you win the second round.
out of the bag labeled . If you can find me an large enough in so that is within for this specific , then you win the second round.
If you can find a function that always guarantee a first-round win, no matter what I choose, then we say 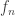 converges uniformly to . We call this uniform convergence, since you don’t need to know where I am in space in order to guarantee me that is close to – i.e. their distance is uniformly bounded. However, if you can never find such an , then I win.
converges uniformly to . We call this uniform convergence, since you don’t need to know where I am in space in order to guarantee me that is close to – i.e. their distance is uniformly bounded. However, if you can never find such an , then I win.
If you can find a function that always guarantees a second-round win, no matter what and I choose, then we say converges pointwise to , since you have to be “wise to the point” I’ve selected in order to guarantee that is close to – i.e. distance is relative to your position in space. If your second-round win is guaranteed “almost surely” (this is a precise term, actually), that is, the values of for which I don’t win has zero measure in , then we say converges pointwise almost everywhere to .
Now here’s the tl;dr: We say that converges to a function
- pointwise if, for all and , there is an
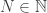 (dependent on both and
(dependent on both and  ) so that
) so that  provided
provided 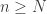 .
.
- uniformly if, for all and , there is an (dependent only on ) so that provided .
Example. Suppose I give you the collection of functions ![f_n: [0,1]\to \mathbb{R}](https://s0.wp.com/latex.php?latex=f_n%3A+%5B0%2C1%5D%5Cto+%5Cmathbb%7BR%7D&bg=ffffff&fg=333333&s=0&c=20201002) given by
given by 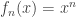 . If you graph these functions you’ll see that the higher exponent smashes the function to zero, except at 1, where it is constant, i.e. converges pointwise to the function
. If you graph these functions you’ll see that the higher exponent smashes the function to zero, except at 1, where it is constant, i.e. converges pointwise to the function

To see why, suppose I give you  and . If
and . If  , pick whatever you’d like in response. Otherwise, then you just need to solve the equation
, pick whatever you’d like in response. Otherwise, then you just need to solve the equation  . So must be at least
. So must be at least  (which is positive since
(which is positive since  ). The cases
). The cases  are trivial, and so you win in round
are trivial, and so you win in round  . But you can never win in round one! Why? For each
. But you can never win in round one! Why? For each  , we see that
, we see that 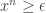 for all
for all 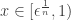 . So no matter what you choose, unless you know the position of , you can’t get uniformly within of .
. So no matter what you choose, unless you know the position of , you can’t get uniformly within of .
Now, suppose you get sick and tired of losing in the first round. So you demand a rule change: at the beginning of each game, you can get rid of as many ‘s as you want out of my bag labeled . But, still wanting to make the game attractive to me, you stipulate that I can limit the proportion of ‘s you take out of my bag, as small as I’d like (provided it’s positive). After all, the problematic set in the example above gets arbitrarily small as  grows, so hopefully you can pull off a win if you can cut that piece out. Egorov’s Theorem shows that, given these modified rules, you can always guarantee a win – in the first turn.
grows, so hopefully you can pull off a win if you can cut that piece out. Egorov’s Theorem shows that, given these modified rules, you can always guarantee a win – in the first turn.
Theorem (Egorov’s Theorem) If , and is a sequence of complex valued functions on that converge pointwise to almost everywhere. Then for every there exists 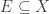 such that
such that  and
and 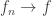 uniformly on
uniformly on  .
.
Proof. Assume without loss of generality that everywhere on (otherwise we can redefine each appropriately). For each  , let
, let
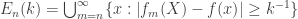 .
.
So  is the set of all values for which
is the set of all values for which  is at least
is at least 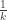 away from . Fix a
away from . Fix a  . The intersection
. The intersection 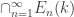 is the set consisting of all for which
is the set consisting of all for which  for all
for all 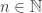 . But everywhere, and so
. But everywhere, and so 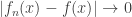 for all . So
for all . So 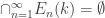 . Moreover, it is easy to see that
. Moreover, it is easy to see that 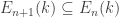 for all .
for all .
Since , the continuity of  from above shows that
from above shows that  as
as 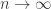 . Let . For each , choose
. Let . For each , choose 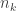 so large that
so large that 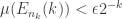 and let
and let  . Then
. Then
 .
.
Now, for all 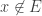 , we have that
, we have that 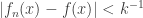 for all
for all  . So uniformly on , as desired.
. So uniformly on , as desired.
I should mention that one may relax the condition that  and instead stipulate that
and instead stipulate that 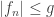 for all and some
for all and some 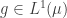 , which follows from the triangle inequality and a simple inclusion argument.
, which follows from the triangle inequality and a simple inclusion argument.
Next time (Friday), I’ll prove the second principle, known better as Lusin’s Theorem. Thanks for reading.


Pingback: Littlewood’s Three Principles (3/3) | whateversuitsyourboat
Pingback: Littlewood’s Three Principles (3/3) | Alexander Adam Azzam