Wow, it’s been a long time since my last post. Sorry about that. I intend (though I’ll make no promises) to post a bit more regularly now.
This final post in my ac series was advertised to be a post about surprising uses of choice, but it’s grown to be a general discussion of ac.
— 1. Important principles weaker than full ac —
To start developing a picture of how ac relates to other mathematical assertions, we need to describe some so-called choice principles that are not provable in zf but are weaker than ac. (See the previous two posts in this series (I and II) for some assertions equivalent to ac.)
One of the most natural ways to weaken ac is to limit the number of choices you’re making or the size of the bins you’re choosing from. By this sort of weakening we come to one of the mildest choice principles, the Axiom of Countable Choice:
Definition 1. The Axiom of Countable Choice (acω) asserts that every countable family of nonempty sets has a choice function. (That is, if  and
and  is countable, then there is a function that assigns each member
is countable, then there is a function that assigns each member  of a member of .)
of a member of .)
acω is substantially weaker than ac, but it’s sufficient to forbid many types of unpleasant sets. For example, it is a theorem of zf+acω that every infinite set has a countable subset, though this isn’t provable in zf alone (that is, there is a model of zf in which there is an infinite set with no countable subset). Many elementary facts about the real numbers can be established in zf+acω; for example, only zf+acω is necessary to prove that a countable union of countable sets is countable (though, again, some form of choice is necessary to prove this). In particular, in the presence of acω, 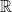 is not a countable union of countable sets. (Apparently the assertion the countable union of countable sets is countable is actually strictly weaker than acω. I think I once found a reference for this.)
is not a countable union of countable sets. (Apparently the assertion the countable union of countable sets is countable is actually strictly weaker than acω. I think I once found a reference for this.)
We need slightly more firepower to do real analysis properly, though. Proofs in (baby) real analysis often require the construction of a sequence, which is typically built inductively by choosing the  th term from, e.g., a ball of radius
th term from, e.g., a ball of radius  . The proof of the Baire Category Theorem is a good example of this style of argument, which uses the Axiom of Dependent Choice:
. The proof of the Baire Category Theorem is a good example of this style of argument, which uses the Axiom of Dependent Choice:
Definition 2. The Axiom of Dependent Choice (dc) is the following assertion: If  is a relation on a nonempty set such that for every
is a relation on a nonempty set such that for every  there is a
there is a 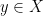 such that
such that  , then there is a sequence
, then there is a sequence  , of members of such that
, of members of such that  for every
for every 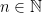 .
.
Apparently this paper gives a proof that the Baire Category Theorem is equivalent (in zf, of course) to dc.
It is straightforward to show that dc implies acω (exercise!). There are many choice principles (like dc and acω) that guarantee only the existence of choice functions for sets satisfying certain size restrictions. (acω restricts the size of the family; other useful choice principles restrict the size of each member of the family.) dc is sufficient to prove the results of basic analysis and is particularly appealing because it is too weak to prove that nasty things like nonmeasurable sets and Banach–Tarski decompositions of the sphere exist. (See section 2 below.)
Notice that acω and dc are local principles, in the sense that they are chiefly concerned with sets of cardinality near 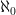 (this is less true of dc). For this reason, it shouldn’t be surprising that each of them is strictly weaker than full ac. Applications outside analysis often require global principles (for sets or spaces of arbitrary cardinality, e.g.), and a popular global choice principle weaker than full ac is the Ultrafilter Lemma.
(this is less true of dc). For this reason, it shouldn’t be surprising that each of them is strictly weaker than full ac. Applications outside analysis often require global principles (for sets or spaces of arbitrary cardinality, e.g.), and a popular global choice principle weaker than full ac is the Ultrafilter Lemma.
Definition 3. The Ultrafilter Lemma (ul) asserts that every filter on a set can be extended to an ultrafilter.
The Prime Ideal Theorem (pit) asserts that every boolean algebra has a prime ideal, an ideal  such that or
such that or 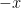 is a member of for every .
is a member of for every .
Conveniently, the ul is equivalent to other interesting choice principles.
Theorem 4. In zf, the following are equivalent:
- The Ultrafilter Lemma;
- The Prime Ideal Theorem;
- The Compactness Theorem for first-order logic.
The proof of this theorem isn’t too difficult, so I won’t provide it here. We are taking on faith that the ul is strictly weaker than ac, but it would be nice to have a sense of just how much weaker it is. We have several different equivalent formulations of ac, each about a different sort of mathematical object:
Theorem 5. In zf, the following are equivalent:
- ac;
- Every set can be wellordered;
- Tychonoff’s Theorem: a product of compact spaces is compact;
- Every vector space has a basis.
(By the way, Exercise: prove that Tychonoff’s theorem implies ac. The proof I know of is short but requires a trick.)
By transferring choice principles over to new contexts (like topology) using the ideas from the proof that the assertions above are equivalent, we can provide a satisfying picture of how much weaker the ul is than ac.
Theorem 6. In zf, the following are equivalent:
- the ul;
- Every product of compact Hausdorff spaces is compact;
- Every product of 2 is compact.
[Edit (Nov 10 2012): the ul is not equivalent to the assertion that every set can be linearly ordered or ac with finite `bins’; in fact,
ul 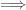 every set can be linearly ordered
every set can be linearly ordered 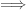 ac with finite bins,
ac with finite bins,
but none of those implications is reversible. It has recently come to my attention (I believe it’s proved in this paper) that the ul is equivalent to Tychonoff’s Theorem for sober spaces.]
Exercise: (Since so many of our authors and readers are analysts) The pit implies Hahn–Banach. (This is apparently difficult, so comment if you think you have a solution. But don’t give it away; I haven’t thought about it much yet.)
— 2. Math(s) without choice —
I’ll say a few words about two results whose proofs don’t require choice, the Cantor–Schroeder–Bernstein Theorem and Ramsey’s Theorem.
That the csb doesn’t require choice is surprising; its conclusion asserts the existence of a function constructed rather mysteriously from the functions in its hypothesis. Of course, it’s easy to say ‘Obviously it doesn’t require choice: here’s a proof that doesn’t use it!’, but when you suppress the intuition you gain by understanding the proof of the csb, the surprise returns. One reason to expect this surprise is that the easiest proof of the csb in zfc (namely, reduce to the case when your sets are wellordered by appealing to ac) makes unavoidable use of choice. And csb provides a mysterious function, which is what ac usually does.
The dual csb theorem, which asserts that if there are surjections 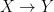 and
and 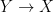 then there is a bijection (and is a theorem of zfc), is not provable in zf. Apparently it is an open question whether the dual csb implies ac.
then there is a bijection (and is a theorem of zfc), is not provable in zf. Apparently it is an open question whether the dual csb implies ac.
Maybe it’s not so surprising that Ramsey’s Theorem doesn’t require ac, but it can be made into a nontrivial choice principle by recasting it as ‘For every  -coloring of the -subsets of an infinite set , there is an infinite monochromatic subset
-coloring of the -subsets of an infinite set , there is an infinite monochromatic subset  of .’ (‘But can’t you just prove this from the normal statement of Ramsey’s Theorem by restricting to a countable subset of ?’, you ask? Remember that it is not provable in zf that every infinite set has a countable subset!)
of .’ (‘But can’t you just prove this from the normal statement of Ramsey’s Theorem by restricting to a countable subset of ?’, you ask? Remember that it is not provable in zf that every infinite set has a countable subset!)
One final note: Solovay proved that it is consistent with zf+dc that every subset of is (Lebesgue-)measurable. So we can do analysis somewhat familiarly in a setting where all of the standard theorems (Heine–Borel, etc.) are true, but pathological nasties like nonmeasurable sets don’t exist. What does such analysis look like? I don’t know, but I’d like to.
— 3. Obviously true? —
The temptation at this point, I think, is to point out theorems we are unable to prove without full ac, and then argue that any theory strictly weaker than zfc provides a somehow deficient concept of set, since it is unable to prove those theorems. My objection to this attitude is that there is a lot of choiceless mathematics to be understood (and alternative extensions of zf (e.g., by the Axiom of Determinacy) that are capable of proving quite powerful, interesting theorems) and we simply gain nothing by asserting (or believing or whatever) that some set of axioms is the gods-given ‘correct’ one and that we should blindly stick to it (in the same way, more absurdly, that a commutative algebraist gains nothing by asserting with religious fervor that noncommutative rings simply don’t exist, in whatever metaphysical sense). Anyway, this is a standard platonism-versus-pluralism issue, and philosophers of mathematics spend a lot of time thinking about it.
— 4. The ‘magic wand’ factor —
Another reason to be careful about (though not necessarily avoid altogether) use of ac is that it is notorious for clouding the ideas in proofs. For example, consider the standard proof in zfc that every countable union of countable sets is countable: Take a countable set of sets 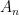 , choose (by acω) an enumeration of each one, and zigzag through the enumerations just as in the proof that
, choose (by acω) an enumeration of each one, and zigzag through the enumerations just as in the proof that  is countable. Contrast that statement and proof to the following:
is countable. Contrast that statement and proof to the following:
Theorem 7. The counted union of counted sets is counted. That is, if 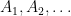 are countably many sets, and for each the function
are countably many sets, and for each the function 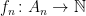 is a bijection, then there is a bijection
is a bijection, then there is a bijection  (and we can write down a formula for it in terms of the
(and we can write down a formula for it in terms of the  ).
).
And, of course, the proof is the same as above, except that the enumerations are already chosen for us. My point is that the standard statement and proof hide the real idea, which is the construction of  from the . If you want the stronger result, just take this theorem and snort the necessary amount of choice. Separating the choice-snorting from the real work gives us a deeper understanding of the result and its proof. Assuming ac carelessly is in the same spirit—though hardly as ridiculous—as assuming
from the . If you want the stronger result, just take this theorem and snort the necessary amount of choice. Separating the choice-snorting from the real work gives us a deeper understanding of the result and its proof. Assuming ac carelessly is in the same spirit—though hardly as ridiculous—as assuming 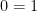 would be: you can prove many things, but without understanding your subject as deeply as you would otherwise. (I should mention that I owe this example, related insight, and the expression ‘snorting choice’ to Thomas Forster.)
would be: you can prove many things, but without understanding your subject as deeply as you would otherwise. (I should mention that I owe this example, related insight, and the expression ‘snorting choice’ to Thomas Forster.)
Recently I encountered another similar example, which I’ll quickly share. I mentioned earlier that the Baire Category Theorem is a theorem of zf+dc. The BCT for separable completely metrizable spaces is actually a theorem of zf. (This isn’t hard to prove, so you should do it if you’re interested. The point is that the countable dense set allows you to make your choices canonical, since you can always take from the countable dense set the lowest-indexed point that does what you need it to do. I think this is a standard trick for proving things about topological spaces without ac, but I don’t know of another example.) I don’t know of a way to get to full BCT from BCT for separable spaces by invoking dc, though, so this isn’t as good an example as the previous one.
— 5. Coming attractions —
I’ve recently gotten excited about infinitary combinatorics, so that will probably be the topic of my next major series. Combinatorial set theory should also show up soon, as will some set-theoretic topology.
I’ll almost certainly write about toposes [sic!] someday, too, but not until after I’ve written a post or two about general category theory.
In other news, Jay has promised to write a post in the next ten days, so stay tuned! P.S. This post is the first I’ve written using Luca Trevisan’s fantastic latex2wp. I recommend it to all math WordPress bloggers! (Quick test: Does WordPress render Erdős correctly? Yes.) Blue, no green!
Two standard references, from which most of this material comes:
Jech, Thomas J. The Axiom of Choice. 2008 Dover edition, originally published as: Studies in Logic and the Foundations of Mathematics, Vol. 75. North-Holland Publishing Co., Amsterdam-London; American Elsevier Publishing Co., Inc., New York, 1973. xi+202 pp. (MR0396271)
Howard, Paul; Rubin, Jean E. Consequences of the axiom of choice. Mathematical Surveys and Monographs, 59. American Mathematical Society, Providence, RI, 1998. viii+432 pp. (MR1637107)






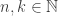
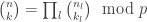



![\mathbb{Z_p}[x]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BZ_p%7D%5Bx%5D&bg=ffffff&fg=333333&s=0&c=20201002)




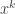


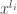


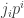
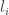

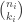

 . This is because the first vote was for
. This is because the first vote was for  , but more importantly it means that since the beginning (when no one had a majority),
, but more importantly it means that since the beginning (when no one had a majority),  , and after the third step it is
, and after the third step it is  . So, again, since the starting position when no one was winning,
. So, again, since the starting position when no one was winning,  the count is at
the count is at  . Note: another way to look at the count at this point is that the number of
. Note: another way to look at the count at this point is that the number of  , meaning at this point no candidate has a majority of the votes. After the next step, though, we are going to dictate that the the count be
, meaning at this point no candidate has a majority of the votes. After the next step, though, we are going to dictate that the the count be 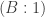 . Note that this pair does not mean that
. Note that this pair does not mean that 
 only means that since the last no-winner point,
only means that since the last no-winner point, 




 . I defined the topology in terms of net convergence, but remarked that this was equivalent to the weak topology generated by
. I defined the topology in terms of net convergence, but remarked that this was equivalent to the weak topology generated by  . The purpose of this post will be to introduce a bunch of different topologies we can put on a Banach space, its dual, and even the set of linear operators on the Banach space. Before I do this however, I want to spend a bit of time reviewing the notion of the weak topology on a space generated by a collection of functions.
. The purpose of this post will be to introduce a bunch of different topologies we can put on a Banach space, its dual, and even the set of linear operators on the Banach space. Before I do this however, I want to spend a bit of time reviewing the notion of the weak topology on a space generated by a collection of functions. be a topological space and
be a topological space and  is a collection of functions, then the weak topology generated by
is a collection of functions, then the weak topology generated by  is the smallest topology on
is the smallest topology on 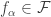 is continuous.
is continuous. , where
, where 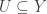 is open in the topology on
is open in the topology on  be as in the above definition and endow
be as in the above definition and endow  in
in  if and only if for every
if and only if for every  , the net
, the net  converges to
converges to 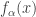 in
in  , then by the continuity of
, then by the continuity of  (for all
(for all  ), we get the result. Conversely, suppose
), we get the result. Conversely, suppose  does not converge to
does not converge to  . Since
. Since 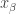 does not converge to
does not converge to  containing
containing  , where
, where  is open (technically we should take distinct sets
is open (technically we should take distinct sets  , but if we intersect these sets, the resulting smaller set works just fine). Now, since this is a finite intersection, the condition that
, but if we intersect these sets, the resulting smaller set works just fine). Now, since this is a finite intersection, the condition that 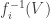 . But this shows that
. But this shows that  is not eventually in
is not eventually in  , a neighborhood of
, a neighborhood of  , hence
, hence  . Typically in point-set topology we are concerned with the first characterization of the product topology, namely it’s generated by finite intersections of cylinders
. Typically in point-set topology we are concerned with the first characterization of the product topology, namely it’s generated by finite intersections of cylinders  , for
, for  . However, let’s see what happens if we consider this in terms of nets. For a finite product, then this says a net
. However, let’s see what happens if we consider this in terms of nets. For a finite product, then this says a net 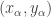 converges to
converges to  if and only if
if and only if  and similarly
and similarly  .
. 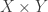 as the set of all functions from
as the set of all functions from  to
to 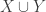 with
with  and
and 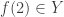 ? Well, this says that
? Well, this says that  if and only if
if and only if  and
and  , in other words it’s a type of pointwise convergence. Suppose
, in other words it’s a type of pointwise convergence. Suppose  denotes the continuous functions
denotes the continuous functions  (or
(or  , either works). We can view
, either works). We can view  , i.e.
, i.e. 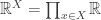 . If we give this space the product topology, then a net
. If we give this space the product topology, then a net  (which need not be in
(which need not be in  for each
for each  for all
for all 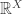 , since, for example, it’s easy to construct continuous functions on
, since, for example, it’s easy to construct continuous functions on  . However, a more natural topology to consider is the so called weak* topology. Recall that we can naturally embed
. However, a more natural topology to consider is the so called weak* topology. Recall that we can naturally embed 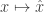 , where
, where 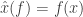 , i.e.
, i.e.  is the so-called evaluation functional. The weak* topology on
is the so-called evaluation functional. The weak* topology on 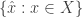 . In terms of nets then, a net in
. In terms of nets then, a net in  , i.e. if and only if
, i.e. if and only if  , the collection of bounded (i.e. continuous) operators
, the collection of bounded (i.e. continuous) operators  . As usual, we have the norm topology (using the operator norm), and the topology of pointwise convergence, which is often called the strong operator topology. We can also consider the weak operator topology, which is best defined in terms of nets. We say
. As usual, we have the norm topology (using the operator norm), and the topology of pointwise convergence, which is often called the strong operator topology. We can also consider the weak operator topology, which is best defined in terms of nets. We say 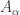 converges to
converges to 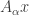 converges weakly to
converges weakly to 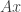 , so the weak operator topology might best be described as the topology of weak pointwise convergence. Now, without further wait, I give you (with proof adapted from Folland)
, so the weak operator topology might best be described as the topology of weak pointwise convergence. Now, without further wait, I give you (with proof adapted from Folland)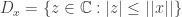 , i.e. to each
, i.e. to each  and note that
and note that  is compact by Tychonoff’s theorem. Now,
is compact by Tychonoff’s theorem. Now,  on
on 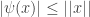 for all
for all  , all the remains to show is that
, all the remains to show is that 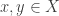 and
and  , we have
, we have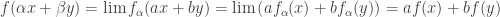
 so that
so that 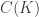 equipped with the supremum norm.
equipped with the supremum norm. be the unit ball of
be the unit ball of 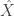 in
in 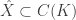 (it’s not immediately clear that
(it’s not immediately clear that 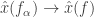 , so indeed
, so indeed  . Clearly the map
. Clearly the map 
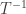 is also bounded, hence
is also bounded, hence  is actually an isometric isomorphism onto its image). The last thing to prove is that
is actually an isometric isomorphism onto its image). The last thing to prove is that 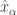 is a net in
is a net in  . Then
. Then 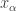 is a Cauchy net in
is a Cauchy net in  , we have
, we have 
 and the proof is complete.
and the proof is complete.![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) and use real valued functions instead of complex valued functions. That’s pretty cool! So, as you can see, the idea of weak topologies is useful and in some sense quite natural when considering normed spaces. Anyways, that’s about all I’ve got for this post, hopefully you enjoyed it.
and use real valued functions instead of complex valued functions. That’s pretty cool! So, as you can see, the idea of weak topologies is useful and in some sense quite natural when considering normed spaces. Anyways, that’s about all I’ve got for this post, hopefully you enjoyed it.
 -low polling numbers, you might suspect that most of the candidates must be working hard to lose the winnability property. Or maybe you thought that Sheldon Adelson would attempt to satisfy the dictatorial property. And yet, at least in theory, neither of those were it. It was the manipulability property that was actually being broken.
-low polling numbers, you might suspect that most of the candidates must be working hard to lose the winnability property. Or maybe you thought that Sheldon Adelson would attempt to satisfy the dictatorial property. And yet, at least in theory, neither of those were it. It was the manipulability property that was actually being broken. is a finite dimensional Hilbert space, then the unit ball of
is a finite dimensional Hilbert space, then the unit ball of  this is obviously true, since the unit ball is closed and bounded. Given any finite dimensional Hilbert space, it is isometrically isomorphic to
this is obviously true, since the unit ball is closed and bounded. Given any finite dimensional Hilbert space, it is isometrically isomorphic to 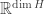 . Under this isomorphism, the unit ball of
. Under this isomorphism, the unit ball of  are two norms on
are two norms on 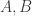 so that
so that  for all
for all 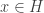 , and as an easy corollary to this we see that any two norms generate the same topology on
, and as an easy corollary to this we see that any two norms generate the same topology on 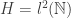 , the set of square summable sequences of complex (or real) numbers with the natural inner product. Let
, the set of square summable sequences of complex (or real) numbers with the natural inner product. Let 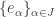 be an orthonormal basis for
be an orthonormal basis for  , the easiest example is to take
, the easiest example is to take  , where the
, where the  occurs in the
occurs in the  be a countable subset of the orthonormal basis. Now, for
be a countable subset of the orthonormal basis. Now, for 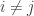 , we have
, we have
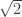 -separated sequence sitting in the unit ball, and so it has no convergent sub-sequence. For a metric spaces, sequential compactness and compactness are equivalent, so this shows the unit ball is not compact.
-separated sequence sitting in the unit ball, and so it has no convergent sub-sequence. For a metric spaces, sequential compactness and compactness are equivalent, so this shows the unit ball is not compact. converges to
converges to 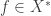 , the net
, the net  converges to
converges to  implies
implies  converges to
converges to  is given by
is given by 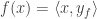 for some fixed vector
for some fixed vector  (and conversely, the map
(and conversely, the map 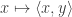 defines a bounded linear functional on
defines a bounded linear functional on  weakly in
weakly in 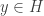 , we have
, we have  . Thus for Hilbert spaces, we can think of weak convergence as “convergence of inner products”. One might ask if this is actually a genuinely weaker topology than the norm topology on
. Thus for Hilbert spaces, we can think of weak convergence as “convergence of inner products”. One might ask if this is actually a genuinely weaker topology than the norm topology on 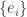 converges weakly to
converges weakly to  . Moreover,
. Moreover, 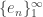 does not converge in the norm topology on
does not converge in the norm topology on 
 . But this is precisely the statement that
. But this is precisely the statement that  . It is left to the reader to verify that this implies
. It is left to the reader to verify that this implies  as
as  , i.e.
, i.e.  weakly in
weakly in 