
Alright, folks. Today’s the day. Today the country votes on who will represent us in government. But more importantly for the news organizations, today is the day when they get to hype the heck out of every exit poll, every demographically significant neighborhood, every weather report, and, of course, every new set of raw vote data.
And if the polls thus far are any indication, it will be late into the evening or early into tomorrow morning until we learn about the results for the day’s biggest race: Ohio (AKA: the presidency).
So how are votes counted and is that indeed the most efficient way possible? What is the complexity of determining the winner of each state?
In a presidential election, each state will have many people on the ballot. Of course Obama and Romney will be there, but Libertarian Gary Johnson will be on the ballot in every state and in DC except possibly Michigan and Oklahoma, where his ballot access has been challenged. The Green Party’s Jill Stein will be on the ballot in 38 states and in DC. The Constitution Party and Justice Party will also be on in a handful of states. And in each state, many more may be on just for that specific state. But more importantly, most states have a write-in option where you can write in a vote for anyone or anything you like; such as yourself or Daffy Duck or Whateversuitsyourboat or Rex Burkhead or Herman Cain.
Nebraska, for instance, has a write-in option. And any name is acceptable for submission. Meaning there is no (finite) bound on the number of possible write-in submissions.
Moreover, let’s assume for the sake of this problem that, although there may be a large collection of write-in submissions for who-knows-whom, that in the end, one of the candidates will get at least 50% of the vote. (This is not a strong assumption for many elections since oftentimes, unless a candidate gets 50% of the vote, there is a runoff election between the two leading vote-getters anyways. And hence there would be another election where getting 50% is actually required.) But for the sake of the algorithm, we cannot and should not narrow down to a finite list who we think will win. We may not immediately say that Obama or Romney will win, because that would put an immediate bias against Whateversuitsyourboat, which is just not right.
Lastly, for this problem we may even assume more broadly that the tally is “on-line”; meaning the votes are coming in one at a time, and we are viewing them only as they come in. So we don’t receive them as a pre-arranged set or know how many will eventually be cast.
Ok, so that’s the setup. Now here’s the question: How many operations must be done in order to determine which candidate got 50% of the vote? Can we find a strategy that is fast and is not dependent on the number of candidates submitted?
Say the candidates are enumerated 1 through 
However, this process is both not nearly as fast as possible and the last step is highly dependent on
I claim there is an algorithm that will deterministically take the, say, 
Note that we did not use in our last algorithm that one candidate will get 50% of the vote, so we definitely want to incorporate that in somewhere. Also note that in the end, we do not care to know the exact vote tallies of all the losers, or even the winner. So keeping track of them seems like we were doing more work than necessary. This is a fun problem to think about. So I encourage you to spend some time mulling it over on your way to the polling booth today, before you come back and read the solution. But if you wish to know the answer right off the bat, well that’s ok too. Here it is.
As your votes come in, put them in a list. Proceed through the list keeping track of two things: one candidate’s name and one number. Say the sequence started like this:

So after thirteen votes, 3 candidates have thus far been recorded. After the first vote, the pair is 



The first non-$A$ vote happens next. After the 


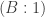

Our conclusion from this is that 
Here’s one way to see it. Note that certainly
And how many steps did our algorithm take? Only one step for each vote. So with
Well, that’s it for this series. I intend to post more often, but you know how that goes. I stopped mid-series last spring. Maybe I will pick that up again. Or maybe I won’t. Who knows. Luckily Hotovy is back with some good analysis posts, Zach claims that he’ll post more this year, and Adam is planning on writing on the Noble Prize in Economics soon. Lots to look forward to! Of course, even with our joined forces we still can’t even begin to compete with the posting rate over at Andy Soffer’s wonderful blog. But hey, we’re only human.
Until next time! Now go watch CNN, all you political junkies!
